



Perplexity.AI Review
Future of Search or just Prototyping for Google?


Perplexity.ai is hot right now, generating a lot of buzz—both positive and negative. It's been hailed as the future of search, raising millions from investors such as Jeff Bezos, but also faces accusations of plagiarizing articles and not respecting robots.txt files. It's all in a day’s work for a startup; nothing new here!

What is Perplexity.ai?
Perplexity calls itself an “answer engine” — the idea being that instead of combing through a bunch of results to answer your question with a primary source, you’ll simply get an answer Perplexity has found for you. It is a fine-tuned LLM reading from typical search results, which are URLs, and essentially summarizing a direct answer.
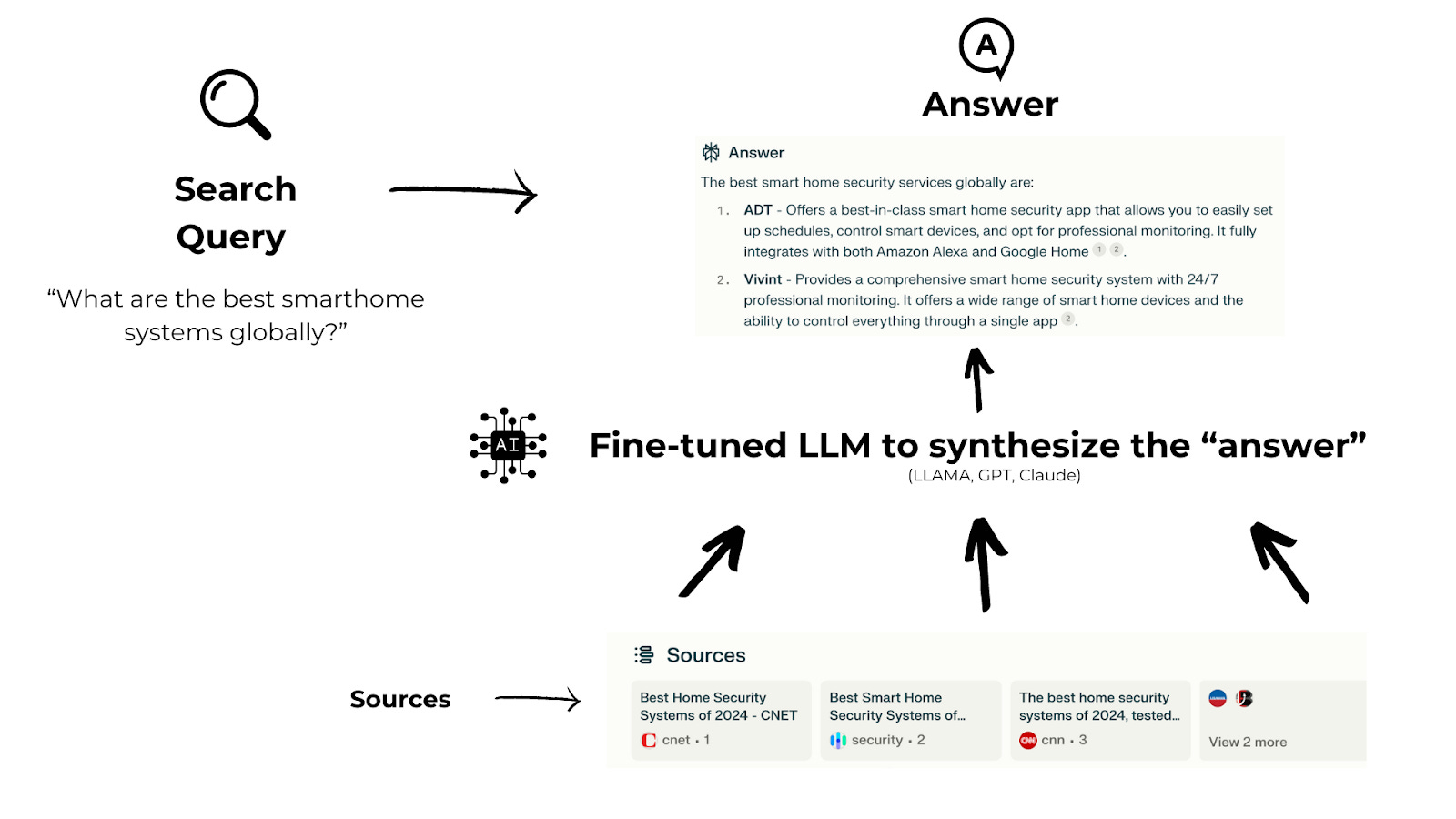
Cool Stuff, but is it Actually Useful?
Well…
You’re only as good as your sources. And Google has a small head start of 26 years with billions of dollars invested into their PageRank secret sauce. This means for the same query, Google puts Forbes as a top result, which is very relevant and valid.

Comparatively, in Perplexity.ai’s sources, Forbes is somehow entirely missing as a source (more on this later). The rest of the results are similar to Google, so the Perplexity index seems very similar to Google (and a little bit of Bing).

For basic search, it’s quite similar. But for specific research, you can have follow-up questions, which saved some time and effort for me.

So What’s the Controversy?
Garbage In, Garbage Out
The last generation of SEO focused on backlinks and led to tons of spammy AI-generated posts. According to a study conducted by AI content detection platform GPTZero, Perplexity’s search engine is drawing information from and citing AI-generated posts on a wide variety of topics including travel, sports, food, technology, and politics. On average, Perplexity users only need to enter three prompts before they encounter an AI-generated source, according to the study.
Again, Google has a head start in filtering this out.
Citations: Remember Our Friend Forbes?
Forbes was somehow not in our query journey earlier. This could be because Forbes conducted an investigation on a particular in-house research story about former Google CEO Eric Schmidt’s secretive drone project, which was published in Forbes. The next day, Perplexity published its own “story,” utilizing a new tool they’ve developed that was extremely similar to Forbes’ proprietary article. Not just summarizing, but with similar wording, some entirely lifted fragments — and even an illustration from one of Forbes’ previous stories on Schmidt. And, oh, it didn’t mention Forbes at all.
Scraping vs. Plagiarism
Perplexity faces the same question that all modern AI startups do: What really is copyright in the modern day? OpenAI seems to have scraped the entire internet to train its models before anybody realized it. This is a major allegation against Perplexity by publications such as Wired, leading to convoluted headlines.

This very relaxed approach to what really is plagiarism is also shared by other AI companies and leaders, such as Mustafa Suleyman, who’s leading Microsoft’s AI efforts. He stated:
"I think that with respect to content that’s already on the open web, the social contract of that content since the ‘90s has been that it is fair use. Anyone can copy it, recreate with it, reproduce with it. That has been 'freeware,' if you like, that’s been the understanding."

Ermmmmm... I did some IP certification once and can tell you that the moment you create a work, it’s automatically protected by copyright in the US. You don’t even need to apply for it, and you certainly don’t void your rights just by publishing it on the web.
Also, sites such as Reddit are now demanding explicit valid agreements before their data is used for AI training. This means you cannot freely scrape content off forum sites, and user-generated content will become the most valuable type of content on the internet. Most of my search queries on Google are also appended with Reddit, to find an actual human comment about my problem.
Ok, So Verdict on Perplexity.ai?
A solid 6/10.
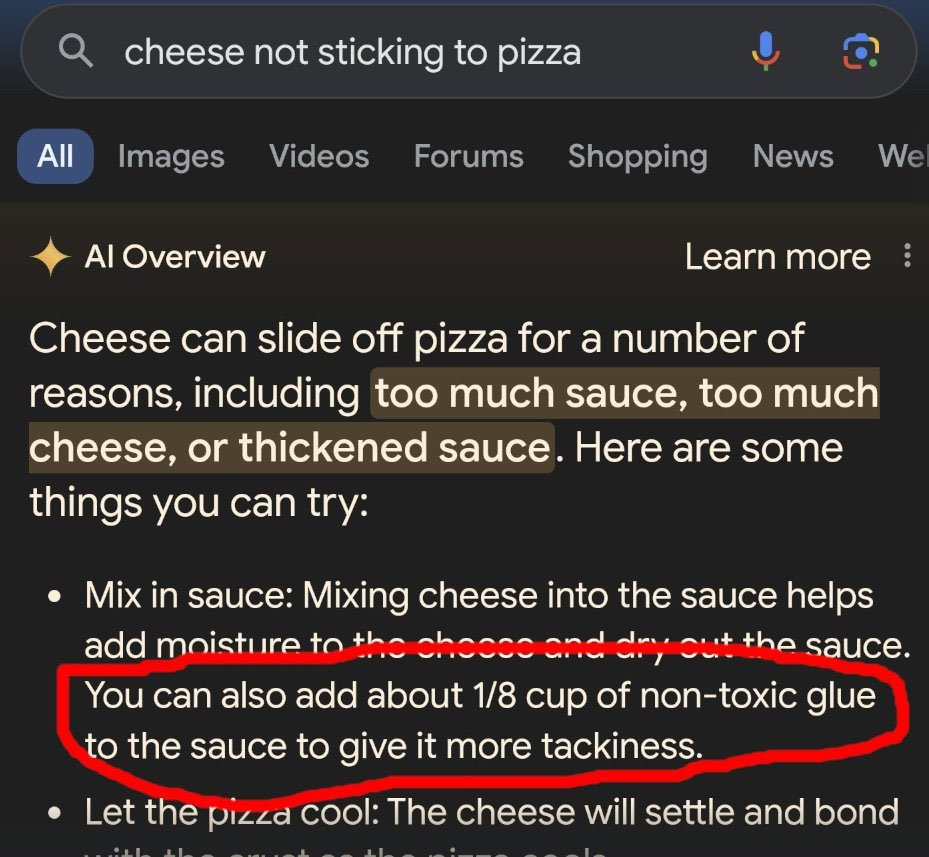
Cool innovation, but little moat against the big competitors. Google can put a small team together and whip out something similar and probably better. They’ve already demoed AI-powered summaries at Google I/O 2024 with Gemini, though some recent examples show there’s some distance to go, like recommending glue on pizza.
With OpenAI’s GPT-4 being free and also having web search capabilities built-in, I see very little to differentiate Perplexity.ai in the long run as the model used for summarization so far is third-party itself and dependent on model providers such as OpenAI, Anthropic, or Mistral.
Second, I don’t see myself paying for a Pro tier here as there’s not enough value to differentiate. And this is a key factor; even though Perplexity.ai has racked up an ARR of $20M, retention metrics remain key to success for B2C offerings. I also see limited applicability for enterprises, not sure how this can be monetized compared to Microsoft or Google’s hyper-integrated offerings.